
Webscraping
This week we are using BeautifulSoup to extract data from websites. Perfect timing, given that for my latest project I needed to build a database of actor information.
To the HTML parser!
Scraping
The first step was to identify where the data I needed was located on the HTML tree. Once found, I created a function to target those HTML tags and grab their text. With the help of these functions, I could run the code over multiple pages and let the information roll in.
The search differed for each piece of data and each source page.
Data source: Box Office Mojo
On Box Office Mojo’s site, I used soup’s “find all” method with regular expressions to match a tag that varied by actor. This code, for example, returns the name of each actor on Box Office Mojo’s people list and adds them to a list of actors.
for link in soup.find_all('a',attrs = {'href':re.compile('/chart/')}):
[actors_FULL.append(str(a.text)) for a in link.find_all('b')]
Screenshot of Box Office Mojo HTML
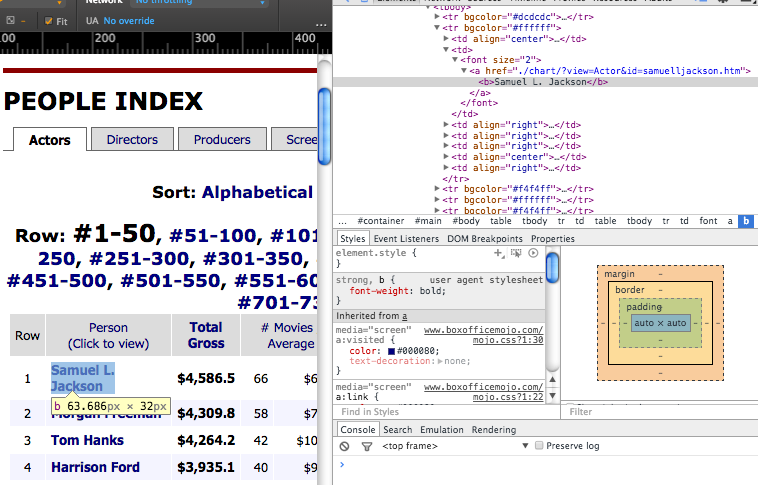
This resulted in about 730 actor names. Dataset, begun.
Data source: Academy Awards Database
On this site, the information I needed was behind a search box. Here I created a post request to submit a search query for Oscar nominees from year 1960 (‘BSFromYear: 33’) to 2014 (‘BSToYear’: 87).
url = "http://awardsdatabase.oscars.org/ampas_awards/BasicSearch"
data = {'action': 'performSearch',
'BSFromYear': 53,
'BSToYear': 87,
'BSCategory': 1061,
'BSCategory': 1062,
'BSCategory': 1063,
'BSCategory': 1064,
'displayType': 1}
response = requests.post(url, data=data)
page = response.text
soup = BeautifulSoup(page,"html.parser")
Then, I used regular expressions again to collect a list of names of all Oscar nominees inside ‘BSNominationID’ tags.
for name in soup.find_all('a',attrs = {'href':re.compile('BSNominationID')}):
osc_names.append(name.text)
Screenshot of Oscars search engine HTML
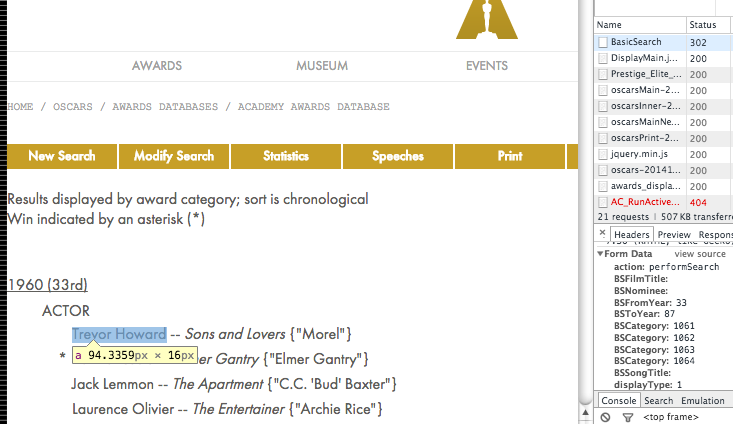
Merging this list with my actors list revealed there were 187 actors from the original dataset that had received at least one oscar nomination.
Data source: Wikipedia
Here I could augment my database with personal information about each actor. This required setting up a loop to parse through the Wikipedia page of every individual actor. Once piece of infomation I pulled was the actor’s reported occupation (labeled “role” or “occupation”, depending on the page). The beginning of the code looks like this:
for actor in df.Actor:
new_name = actor.replace(" ","_")
url = "https://en.wikipedia.org/wiki/"+new_name
response = requests.get(url)
page = response.text
soup = BeautifulSoup(page,"html.parser")
try:
writer.writerow((actor,soup.find(class_="role").text))
except:
try:
writer.writerow((actor,soup.find(scope_="Occupation").text))
except:
writer.writerow((actor,"None"))
Running the code, I found many actors’ pages were not accessed. Why? Because their URL was not built as easily as adding an underscore between their first and last name. A quick fix was modifying the code to catch those pages which end in “(actor)”.
try: writer.writerow((actor,soup.find(class_="role").text))
except:
try:
writer.writerow((actor,soup.find(scope_="Occupation").text))
except:
try:
url = "https://en.wikipedia.org/wiki/"+new_name+"_(actor)"
response = requests.get(url)
page = response.text
soup = BeautifulSoup(page,"html.parser")
writer.writerow((actor,soup.find(class_="role").text))
except:
try:
writer.writerow((actor,soup.find(scope_="Occupation").text))
except:
writer.writerow((actor,"None"))
In the end I successfully pulled Wikipedia info on about 95% of my original actors list from Box Office Mojo. The rest I inputted manually, something feasible for the small scale of my dataset. For a greater empty value size, I might try using Wikipedia’s search box instead, using key words such as “Actor” or “movie” alongside the actor’s name to identify the correct Wikipedia page.
Make it usable
Cleaning was a continual process as I found more and more uses for my dataset.
To begin with, I converted each variable I had collected into its appropriate data type. Unicode to string (saving as csv then loading back into python was one solution), dates to datetime objects, strings to ints, stripping excess whitespace, etc.
Then, I used my existing variables to create more features. For example:
Current age using their birthdate:
def calc_age(bday):
today = datetime.date(datetime.now(pytz.utc))
return today.year - bday.year
Filter for acting as principal occupation:
df['Occ_act_dummy'] = df['Occupation'].map(lambda x: 1
if x.lower().startswith("actor") or x.lower().startswith("actress")
else "None" if x=="None" else 0)
Gender based on actor or actress designation:
df['Gender']=df['Occupation'].map(lambda x: 0
if "actor" in x.lower()
else 1 if "actress" in x.lower() else "Unknown")
So fresh and so clean
After much toiling, creating, destroying and learning, I ended up with a complete dataset of 617 observations (actors with acting as primary occupation).
codebook = {
"Actor": "Name of actor or actress (617 obs)",
"Total_Gross_2015_Dol": "Amount grossed by films featuring this actor (Box Office Mojo)",
"Num_movies": "Number of movies used to calculate total gross (Box Office Mojo)",
"Avg_Gross": "Total gross divided by number of movies",
"Birthday": "Actor's birthday (source: Wikipedia)",
"Occupation": "Actor's occupation (source: Wikipedia)",
"Gender": "Actor's gender",
"Num_months_rec_pd_15_20": "Count of months of US economic recession between ages 15-20 (based on NBER economic indicators)",
"Num_months_rec_pd_20_25": "Count of months of US economic recession between ages 0-15 (based on NBER economic indicators)",
"Age": "Age of actor",
"Career_start": "Year acting career began (source: Wikipedia)",
"Years_acting": "Length of acting career",
"Num_osc": "Number of Oscar nominations"
}
So, why did I grab this data? Why do I need to know Harrison Ford’s birthday? Check back for an upcoming post on the analysis process.